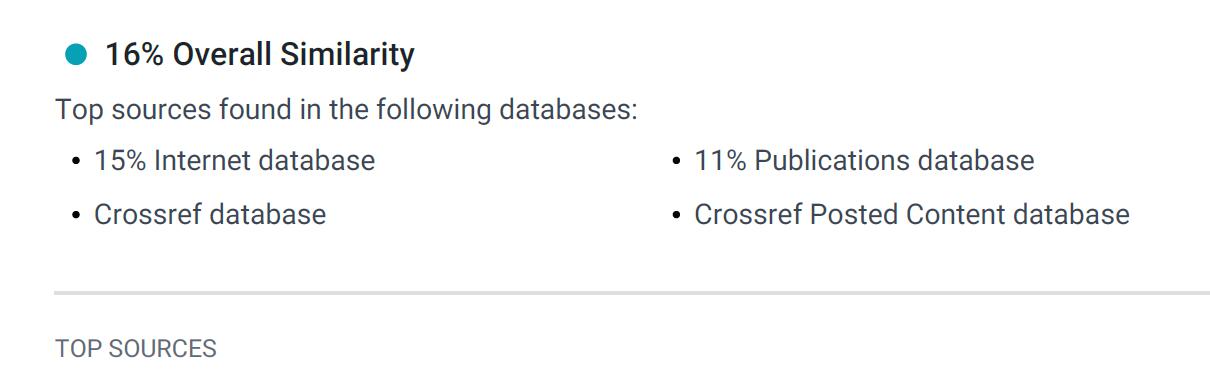
在使用 iThenticate 进行论文相似性检测时,很多作者都会注意到查重报告中会标注不同的来源类型,其中最常见的就是 Crossref database 和 Internet database,不少作者可能会产生疑问,这两类数据库究竟有什么区别?为什么同样是相似内容,却会被归到不同的来源下?
一、Crossref database:以正式学术出版物为核心
Crossref database 指的是通过 Crossref 体系参与相似性检测的学术出版内容,其核心特点是:正式、可追溯、以出版机构为主体。
这类来源通常包括:
- 国际期刊论文(SCI、SSCI、EI 等);
- 正式出版的会议论文;
- 出版社授权的图书章节、专著;
- 已注册 DOI 的 OA 论文和预印本;
- 部分学位论文(由机构注册并授权);
这些内容的共同点在于:
- 有明确的出版主体(期刊社、出版社、学会);
- 大多已分配 DOI;
- 版权关系清晰;
- 常被期刊编辑视为高权重来源;
在查重报告中,如果相似内容主要来自 Crossref database,编辑通常会更加关注,因为这意味着稿件与已正式发表的学术成果存在文本重合。
二、Internet database:开放网络内容的集合
与 Crossref 相对,Internet database 指的是来自开放互联网的文本内容,其覆盖范围更广,但学术规范性和稳定性相对较弱。
常见来源包括:
- 学术网站或机构网页;
- 个人主页、实验室网站;
- 技术博客、教学讲义;
- OA 平台中未注册 DOI 的内容;
- 部分会议官网发布的论文摘要或全文;
- 网络报告、政策文件等;
这类内容的特点是:
- 不一定属于正式出版物;
- 来源多样,更新频繁;
- 版权和版本稳定性较弱;
- 学术权威性不一;
因此,Internet database 更像是对公开可获取文本的补充,用于防止论文与网络已有内容出现明显重复。
三、两类数据库在查重结果中的实际差异
从查重结果解读角度看,Crossref database 和 Internet database 的差异主要体现在以下几个方面:
- 学术风险权重不同
- Crossref 来源的重复,通常被视为学术层面的高度敏感问题;
- Internet 来源的重复,更偏向“公开内容重合”,风险需结合具体来源判断;
- 编辑关注重点不同
- 编辑更关注是否与已发表论文(Crossref)高度重合;
- 对网络来源,通常会查看是否为通用表述或非学术文本;
- 版本差异导致的多源匹配
同一篇文章可能同时出现在期刊官网(Crossref)和网络镜像页面(Internet),在报告中被列为两个不同来源,这是正常现象,并不代表重复加倍。
四、是否应只关注 Crossref database 的重复?
这是一个常见误区,在实际审稿中,编辑并不会只看 Crossref database,而是结合整体相似度和内容性质综合判断。例如:
- 如果 Internet database 的重复来自高质量学术平台或完整论文文本,其风险并不一定低于 Crossref;
- 如果 Crossref 的重复主要集中在方法描述、标准定义或作者自引部分,问题也未必严重。
关键不在于来自哪里,而在于:
- 重复内容出现在哪个章节;
- 是否构成实质性文本重合;
- 是否存在合理引用和说明;
五、作者应如何正确应对?
在解读查重报告时,建议作者:
- 分别查看 Crossref 和 Internet 的相似内容,不要只看总比例;
- 优先处理来自 Crossref 的高比例重合段落;
- 核查 Internet 来源的具体页面性质,区分学术内容与通用文本;
- 避免仅依赖某一数据库的低重复判断原创性。
总体而言,Crossref database 更偏向正式学术出版体系,是编辑判断学术重复风险的重要依据;Internet database 则用于补充网络层面的文本比对。两者在来源性质、学术权重和解读方式上均存在明显差异,但在查重判断中缺一不可。
理解这一区别,有助于作者更理性地看待 iThenticate 查重结果,也能在投稿前更有针对性地修改稿件,降低不必要的审稿风险,不过,查重需要使用正品的iThenticate系统,如iThenticate中文网站,如果用了假冒的,查出来的结果可能就不具有参考性了。



